

PyhtonでchromeなどのWebブラウザを自動操作して手作業を自動化したいと困っていませんか?
ルーチン作業を自動化するRPA(Robotic Process Automation)のようにPythonでもSeleniumライブラリを利用することでブラウザの自動操作できます。
私はSeleniumを使い始めた当初はエラーが多く上手くいかないことだらけでした。原因はchromeブラウザのバージョンを都度合わせる必要があったり、Webサイトの情報を正確に取得するための待機方法やPath指定方法を明確に理解していなかったからです。
現在は上記の課題を解決してSeleniumを快適に利用できておりますのでこの経験を活かして気を付けるポイントやSeleniumを楽に利用する方法についてご紹介していきたと思います。
- 実際のWebサイトで動くスクリプトを知りたい
- Seleniumとブラウザのバージョン違いを自動化したい
- 自動化するための色々なパターンを知りたい
- エラーを回避する方法を知りたい
ブラウザ自動操作の準備
今回ご説明する検証環境です。
・Windows10
・seleniumバージョン3.141.0
・Chrome
※firefoxやedgeでも可能
Seleniumを使ってChromeブラウザを簡単に自動操作する為には下記2つの事前準備が必要です。
- Selenium
- Webdriver_manager ※ブラウザとdriverのバージョンを自動で合わすために必要
Seleniumのインストール
Seleniumはバージョンが違うと動かないケースがあるので、今回は私のコードで確実に動くバージョンを指定してダウンロードします。
pip install selenium == 3.141.0python selenium ドライバー 自動アップデート
普通にChromeDriverをインストールするとChromeブラウザのバージョンアップにあわせて、都度バージョンを合わせる必要があり、これをしないと下記のようなエラーがでます。
This version of ChromeDriver only supports Chrome version
毎回自動でバージョンを合わせるのが
Webdriver_managerです!
手動修正は手間ですし自動化のメリットが損なわれてしまいます。そこでこれを自動化するライブラリをインストールします。
Webdriver_managerのインストール
webdriver_managerというライブラリを利用するとWebブラウザのバージョンに合わせたdriverをダウンロードしてくれますのでseleniumを利用する場合は毎回下記コマンドを実行されるようにしておけばバージョン合わせの苦労から解放されます。
pip install webdriver-managerjupyter notebook上で毎回実行したい場合は下記のように先頭に「!」をつければコマンドプロンプトと同じ結果が得られます。
!pip install webdriver-manager実際に動くコードの紹介
ライブラリのインポート
よく利用するものをインポート文に入力しましたのでコピペでご利用ください。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.options import Options
import time
import requests
import shutil
import urllib
import os検証用の全コード
実際にブラウザを自動操作するコードを提供することで、技術を習得しやすくしました。
今回用意したコードはヤフーサイトのTopページにアクセスしてキーワード入力やクリックなどをいくつかのパターンで実行したものになり、全コードは下記です。
#変数
target_url = "https://www.yahoo.co.jp/"
input_text = "2つむじchannel"
##ここから実行文
#URLへアクセス
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(target_url)
#全コンテンツが読み込まれるまで待機
try:
WebDriverWait(driver,15).until(EC.presence_of_all_elements_located)
except TimeoutException as e:
print(e)
#①KW入力例を4つ紹介
#cssセレクターで指定(検索欄に入力)
driver.find_element_by_css_selector("#ContentWrapper > header > section._1o9PYyvuVafb5hd9eJ9rYX > div > form > fieldset > span > input").send_keys(input_text)
#Xpathで指定
driver.find_element_by_xpath("/html/body/div/div[1]/header/section[1]/div/form/fieldset/span/input").send_keys(input_text)
#nameで指定
driver.find_element_by_name("p").send_keys(input_text)
#classで指定
driver.find_element_by_class_name("_1wsoZ5fswvzAoNYvIJgrU4").send_keys(input_text)
#②テキスト名の取得例(mail欄)
text_1 = driver.find_element_by_xpath("/html/body/div/div[1]/main/div[3]/div[2]/article[1]/div/div/div[2]/section/div/ul[1]/li[1]/a/dl/dt/span").text
#③画像の取得方法
#src属性を取得
get_src = driver.find_element_by_xpath("/html/body/div/div/main/div[3]/div[1]/div[2]/a/img").get_attribute("src")
#画像を保存
def get_image(input_src,out_path):
#画像URLからバイナリを読み込む
with urllib.request.urlopen(src) as rf:
image_data = rf.read()
#バイナリデータを画像の拡張子形式で書き出す
with open(out_path,mode="wb") as wf:
wf.write(image_data)
return
#リンクのhref属性の取得(ニュース一覧の先頭リンクを取得)
get_href = driver.find_element_by_xpath("/html/body/div/div[1]/main/div[2]/div[1]/article/div/section/div/div[1]/ul/li[1]/article/a").get_attribute("href")
#windowsサイズを最大化
driver.maximize_window()
#スクリーンショット
desktop_dir = os.path.expanduser("~/desktop")
image_ = "test.jpg"
driver.save_screenshot(desktop_dir + "/" + image_)
#検索ボタンクリック
driver.find_element_by_xpath("/html/body/div/div[1]/header/section[1]/div/form/fieldset/span/button/span").click()
#推奨の書き方(上記例を修正)
#driver.find_element(By.XPATH,"/html/body/div/div[1]/header/section[1]/div/form/fieldset/span/button/span").click()
print(get_href)
print(get_src)ここからは上記コードにたいして個別にコードの説明をしていきます。
指定URLへのアクセス方法
最初のゴールばseleniumを利用して指定URLを自動的に開けるか?になります。
この動作が確認できれば「seleniumが正常にインポートされている」、「ブラウザのバージョンがあっている」の2点が確証できます。
URL立ち上げまでのコードは下記です。
#変数
target_url = "https://www.yahoo.co.jp/"
##ここから実行文
#URLへアクセス
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(target_url)
webdriver.Chrome(ChromeDriverManager().install())と記載することでブラウザのバージョンを自動的にあわせてその情報を記録します。
その後driver.get(変数)により指定URLを開くことができます。
Webページ取得の待機方法
seleniumはWebサイトの情報を取得することで自動操作が可能ですが、Webサイトが読み込まれる前にseleniumで指令を出すと「そんなものないよ~」とエラーになります。
実はここが結構重要です!
seleniumを利用し始めてコードはあっているんだけどエラーで止まるな~という時はだいたいこのケースであり、エラーを防止する為に大きく下記2つの機能がseleniumには用意されております。
- 明示的な待機の方法(WebDriverWait)
- 暗黙的な待機(implicitly_wait)
明示的待機とは
あらかじめ定義した条件が満たされるまで待機することで代表的な方法は下記2つです。
- WebDriverWait
- time.sleep()
WebDriverWaitを利用することで指定条件の状態になるまで待機することができます。
指定条件をクリアしたことが確認できた段階で役目が終わり次のコードを読みにいくので、待機時間も最小限で済みます。
time.sleepは指定した秒数だけ待つ方法ですので3秒と入力すれば3秒待って次の処理にいくためWebDriverWaitと比較すると無駄な待ち時間が発生してしまいますが、WebDriverWaitを利用しても制御できなものがあった場合にtime.sleepを利用する手があります。
WebDriverWaitの使い方
WebDriverWaitを利用したコードです。(全コンテンツが読み込まれるまで待機の例)
#全コンテンツが読み込まれるまで待機
try:
WebDriverWait(driver,15).until(EC.presence_of_all_elements_located)
except TimeoutException as e:
print(e)WebDriverWait() の第1引数はWaitさせたいWebDriverを記載し、第2引数はタイムアウト値を指定します。
untilの中には 「WebDriverを待機させ続ける条件を記載」するもので今回は全コンテンツが読み込まれるまで待機する例を記載しておりますが、HTML要素の存在をチェックするための関数はいくつもありますので例を記載します。
| メソッド | 条件 |
|---|---|
| visibility_of_element_located | 指定した要素の表示される |
| text_to_be_present_in_element | 指定したテキストが表示される |
| presence_of_all_elements_located | ページ内のすべての要素が読み込まれる |
| presence_of_element_located | DOM要素内に指定した要素が現れる |
| alert_is_present | Alertが表示される |
| element_to_be_clickable | 要素がクリック出来る状態になる |
おすすめはvisibility_of_element_locatedであり、理由としてJavaScriptのように画面遷移が変わる場合は要素がでてくるまで待つ必要がでてくるためです。
暗黙的待機とは
明示的な待機のようにその都度条件を記載しないので暗黙的待機と言われ、seleniumで取得したい条件の前にimplicitly_wait(待機秒数)を記載します。
#変数
target_url = "https://www.yahoo.co.jp/"
input_text = "2つむじchannel"
##ここから実行文
#URLへアクセス
driver = webdriver.Chrome(ChromeDriverManager().install())
driver.get(target_url)
#全コンテンツが読み込まれるまで待機
try:
WebDriverWait(driver,15).until(EC.presence_of_all_elements_located)
except TimeoutException as e:
print(e)
#cssセレクターで指定(検索欄に入力)
driver.find_element_by_css_selector("#ContentWrapper > header > section._1o9PYyvuVafb5hd9eJ9rYX > div > form > fieldset > span > input").send_keys(input_text)
上記の例では検索欄のhtml要素をcssセレクターで指定する前にimplicitly_wait()を入れることでセレクターの要素が出てくるまで最大10秒待ちますが、要素が特定できれば10秒よりも早く次の処理に進みます待機します。
html要素の取得方法とブラウザ自動操作
ここからは対象Webサイトのhtml要素をどのように取得し、seleniumで自動操作するかの説明を致します。
まず、seleniumで要素を選択する方法はdriver.find_element_by・・・で指定します。
・・・の部分ですが指定する方法がいくつかありますので記載します。
html要素を取得するコード例
driver.find_element_by_id(条件を入力)
driver.find_element_by_name(条件を入力)
driver.find_element_by_xpath(条件を入力)
driver.find_element_by_link_text(条件を入力)
driver.find_element_by_partial_link_text(条件を入力)
driver.find_element_by_tag_name(条件を入力)
driver.find_element_by_class_name(条件を入力)
driver.find_element_by_css_selector(条件を入力)複数の要素を見つけるにはelementをelementsに変えてdriver.find_elements_by・・・で指定します。
driver.find_elements_by_id(条件を入力)
driver.find_elements_by_name(条件を入力)
driver.find_elements_by_xpath(条件を入力)
driver.find_elements_by_link_text(条件を入力)
driver.find_elements_by_partial_link_text(条件を入力)
driver.find_elements_by_tag_name(条件を入力)
driver.find_elements_by_class_name(条件を入力)
driver.find_elements_by_css_selector(条件を入力)ここの「条件を入力」はChromeの検証機能(デベロッパーツール)で要素を取得するのが簡単です。
Chromeのデベロッパーツールで要素を取得
chromeのデベロッパーツールを使い対象サイトから要素を取得する方法をヤフーサイトを例に説明致します。
- クロームでヤフーサイトを開く
- 適当な場所で右クリックし、表示された検証をクリック(デベロッパーツールが開く)
- 要素を取得したい場所にカーソルをあてて、再度「検証」をクリックする
- 対象htmlの場所に移動するので、更に右クリックしてCopyを選びCopy selectorを選択
※xpath,class,nameなどいくつか方法あり
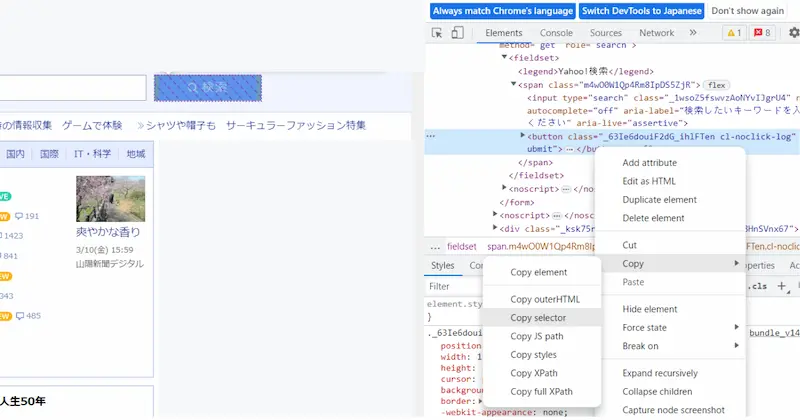
これらを使うことで要素を取得できたと思います。
クリック driver.find~.click()
次に選定した要素にたいしてどのような動作をしたいかを指示します。
クリックする方法はdriver.find_element_by・・・・・.click()を使い、下記のように要素選択後の最後に追加します。
driver.find_element_by_xpath(要素を入力).click()
driver.find_element_by_css_selector(要素を入力).click()テキスト入力 driver.find~.send_keys()
検索欄などにテキストを入力したい場合はdriver.find_element_by・・・・・.send_keys()を使います。
driver.find_element_by_css_selector(要素を入力).send_keys()件数が少なければ.send_keys()で問題ないのですが、データ量が多い場合は.send_keys()だと1レコード単位で読み込むので時間がかかる場合があるので、他の方法としてテキストを高速入力する方法をご紹介します。
テキスト高速入力 seleniumからJavaScript実行 driver.execute_script
#直接入力
driver.execute_script('document.getEIementsMyName(p)[0].value="ここに入力値を記載"')
#変数を使った入力 ※変数text_1に文字をいれておく
driver.execute_script('document.getEIementsMyName(p)[0].value="%s"; % text_1')
#リストの場合 ※変数list_1にlistをいれておく
driver.execute_script('document.getEIementsMyName(p)[0].value="%s"; % list_1')テキスト名の取得 driver.find~.text()
次はテキスト名を取得する方法としてdriver.find_element_by・・・・・.textを利用します。
driver.find_element_by_css_selector(要素を入力).textリンク名取得 driver.find~.get_attribute(“href”)
リンクのhref属性を取得するにはdriver.find_element_by・・・・・.get_attribute(“href”)を利用します。
クロームのデベロッパーツールでは「href」があるところにカーソルをあわせて右クリックします
driver.find_element_by_css_selector(要素を入力).get_attribute("href")画像ファイルの取得 driver.find~.get_attribute(“src”)
画像ファイルを取得する為にはまずsrc属性をdriver.find_element_by・・・・・.get_attribute(“src”)を利用して取得します。
クロームのデベロッパーツールでは「src」があるところにカーソルをあわせて右クリックします
get_src = driver.find_element_by_css_selector(要素を入力).get_attribute("src")src属性入手後に画像ファイルを入手するための関数を作成し、インプット情報としてsrc属性と画像ファイルを保存するパスを指定します。
#画像を保存
def get_image(input_src,out_path):
#画像URLからバイナリを読み込む
with urllib.request.urlopen(src) as rf:
image_data = rf.read()
#バイナリデータを画像の拡張子形式で書き出す
with open(out_path,mode="wb") as wf:
wf.write(image_data)
returnスクリーンショット driver.save_screenshot(path)
seleniumでスクリーンショットを撮ると時はdriver.save_screenshot(image_)を使います。
#エビデンスが見やすいようにwindowsサイズを最大化
driver.maxmize_window()
#スクリーンショットを撮る
driver.save_screenshot(image_file_path)更に詳しく知りたい方は下記のselenium公式ドキュメントをご覧くださいませ。
seleniumが急に使えなくなった場合の対策
seleniumが使えなくなるケースとしてバージョン違いもありますが、proxyと証明書の問題の場合は対応につまづくことがあります。
更に、他のselenium事例やスクレイピングについて知りたい方は一度下記を読むことをお勧めいたします。seleniumなどのWebブラウザ操作やスクレイピングのbeautifullsoup、クロールのscrapy,requestsについて説明されており、Webサイトを思いのままデータ取得したい方向けの本です。私自身いくつか本を読みましたがこちらが一番わかりやすく実践できるものが多かったのでお勧めです。
コメント