
Pythonを利用してエクセルやcsvなどのデータ加工をしたいけどやり方がわからないと困っていませんか?
私はPythonを学び始めた時にはエクセルファイルの読み込みエラーや文字化け、データを絞り込む方法もいくつかあるので悩んでおりました。
現在は色々経験し一番楽だと感じたPandasを利用し、明確な知識を身に着けたことで操作に困ることはなくなり、快適に自動化するためのコード作成ができています。
今回はPandasの利用イメージを明確に理解するために私が作成したサンプル用データを用意しましたので、Pythonサンプルコードと共に実体験することで皆様が理解を深められればと思っています。
- 実際のデータでPandasを使いたい
- エクセルやcsvファイルを読みこみたい
- 条件によるデータ抽出やテーブル結合がしたい
Pandas環境の準備 Windows
私が実践した検証環境とPandasのインストール方法から説明していきます。
<今回ご説明する検証環境>
・Windows10
・Pandasバージョン1.4.4
・jupyter notebook
Pandasのインストール
今回の実践内容であれば私のPandasとバージョンを合わせなくても動くと思いますので下記コマンドでインストールします。
pip install pandasもし、私のPandas環境と合わせたい場合は== 1.4.4をつけてインストールします。
pip install pandas== 1.4.4コマンドプロンプトではなく、jupyternotebookのセルでインストールする場合は先頭に!をつけてください。
!pip install pandas今回の検証はcsvファイルのみ使用しますが、もしエクセルファイルもPandasで使いたい方は「xlrd」のインストールも必要になります。
pip install xlrdライブラリのimport
Pandasを動かす為には最初にimportする必要がありますので下記に記載します。
import pandas as pd実行後に下記エラーとなった場合はPandasのインストールに失敗しておりますので上記のインストール方法を再度ご確認願います。
ModuleNotFoundError: No module named ‘pandas’
サンプルCsvデータの説明
約200行のcsvデータを2つ用意することでデータ結合の体験ができるようにしております。
sample_1とsample_2をデスクトップ上にダウンロードして当サイトの練習用にご利用ください。
Csvを読み込む方法
jupyternotebook上でcsvを読み込むにはpd.read_csv(ファイルpath)と記載しますが、windowsの場合は、ファイルpathをそのまま指定すると\がエスケープシーケンスとみなされてエラーになります。
対応策としてpathの先頭にraw文字(rを付ける)ことでエスケープシーケンスとみなさずに表記のまま解釈させることで対応します。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv")もしお手持ちのエクセルファイルで試したい場合は「pd.read_excel」とします。
pd.read_excel(r"C:\Users\abi00\Desktop\sample_1.csv")sample_1.csvの上から5行を表示したイメージは下記ですので同じデータが読み込まれたと思います。
| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-22 | おやつ | たいやき | 4000 | 1 | 4000 | 4 | 栗たいやき |
実践では色々なPandasの読み方が必要になると思いますので代表的なものをご紹介してきます。
文字化けの対応はencoding
python環境の文字コードはutf-8ですが、ファイルを読み込んだ時にUnicodeDecodeError: ‘utf-8’ codec can’t decode byteになった場合や文字化けしている場合は文字コードがutf-8ではないのでencodingしないと適切に読み込むことができません。
Pandasではオプションのencodingを用いて文字コードを指定し、shift-jisやshift-jis0213,windows拡張文字列が混ざっている場合は「cp932」を用います。
#shift-jisの場合
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",encoding="shift-jis")
#shift-jis0213の場合
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",encoding="shift-jis0213")
#cp932
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",encoding="cp932")上記のどれかを使えば大抵は読み込めると思います
データ型の指定はdtype
テキストファイルを読み込む時に型指定をしないと自動判断で型が決まりますが、型が違うと意味が変わってしまう場合があるので注意が必要です。
1つ例をあげますとデータ管理番号として0から始まる「001」があった場合に文字型ではなく数値型で読み込むと「001」は1と変わり違う意味になるためデータを扱う点で危険です。
この問題を解決する為には文字を指定して取り込む必要があるので、今回は全ての文字列を同じ型にする方法と個別にデータ型を設定する方法の2つをご紹介致します。
全ての項目を文字列として読み込む為にはオプションの「dtype=str」を記載します。
#全て文字列読み込み
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",dtype=str)個別にデータ型を設定する方法は、型指定したい項目のみ辞書形式{}で記載すれば指定型で取り込み可能です。
指定していない項目は自動で型が選択されます。全ての型を指定することは大変ですので、意味が変わってしまう型に注力し、型指定することにしています。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",dtype={'商品ID': str,'売上数量': "float64"}))行指定で読み込み
テキストデータを読み込む時にheaderの有無や何行目から読み込むなど指定することも可能です。
headerなしで読み込み
sample_1.csvをheaderなしで読み込むにはheader=Noneを指定して読み込むと新しいレコードが増え連番が列名として振られます。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",header=None)| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
特定行から読み込み
csvファイルを特定の行から読み込みたい場合は「header=数字」を使えば可能で今回の例では「header=2」として2行目からデータを取り込むように指定しました。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",header=2)この場合はそれより上の行は無視され取り込まれまず、下記結果になります。
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
|---|---|---|---|---|---|---|---|
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-22 | おやつ | たいやき | 4000 | 1 | 4000 | 4 | 栗たいやき |
| 2020-01-19 | おやつ | たいやき | 4000 | 1 | 4000 | 5 | クリームたいやき |
| 2020-08-26 | おやつ | たいやき | 4000 | 6 | 24000 | 6 | くりたいやき |
特定行をスキップして読み込み skiprows
スキップする行を指定する方法はskiprows=[]と記載し、list内にスキップしたい行を指定します。下記例では、2行目と5行目を取り込まないようにしました。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",skiprows=[2,5])| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-19 | おやつ | たいやき | 4000 | 1 | 4000 | 5 | クリームたいやき |
| 2020-08-26 | おやつ | たいやき | 4000 | 6 | 24000 | 6 | くりたいやき |
最初の数行だけ読み込み nrows
大きいサイズのデータを読み込むと待ち時間がかかりますが最初の数行だけを読み込むオプションの「nrows=数値」を使うと時間短縮できます。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv",nrows=2)| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
列指定で読み込み usecols
列を指定してファイルを読み込む方法ですが「読み込みたい列を指定する方法」と「読み込まない列を指定する方法」の2種類があります。
列を指定してデータを読み込む場合はオプション「usecols」を指定すれば列番号や列名で指定できます。
#1列目、3列目を絞り込む
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv", usecols=[1, 3])
#列名で指定する場合は下記
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv", usecols=["大カテゴリ","単価"])| 大カテゴリ | 単価 |
|---|---|
| おやつ | 4000 |
| おやつ | 4000 |
| おやつ | 4000 |
| おやつ | 4000 |
| おやつ | 4000 |
特定列を除外した方が楽な場合は除外したい項目をlambdaを利用してusecols=lambda x: x not in [] のようにlist式で指定します。
pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv", usecols=lambda x: x not in ['大カテゴリ', '単価'])| 売上日 | 中カテゴリ | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|
| 2020-06-27 | たいやき | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | たいやき | 5 | 20000 | 1 | たいやきおれんじ |
| 2020-12-22 | たいやき | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | たいやき | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-22 | たいやき | 1 | 4000 | 4 | 栗たいやき |
Pandas公式ドキュメントのファイル読み込みはこちらです。
エクセルのSheet指定で読み込み sheet_name
お手持ちのエクセルデータで試したい方向けにエクセルのSheetを指定して読み込む方法をご紹介致します。
エクセルの全Sheetを読み込むなら「sheet_name=None」を利用します。
複数Sheetを読み込むなら「sheet_name=[“”,””]」とリスト型で読み込みたいSheetを指定します。
#全てのSheetを読み込む
pd.read_excel(path, sheet_name=None)
#複数SheetをSheet名称で指定する
pd.read_excel(path, sheet_name=["Sheet1","Sheet2"])
#複数SheetをSheet番号で指定する
pd.read_excel(path, sheet_name=[0,1])
#複数SheetをSheet名とSheet番号を混合して指定する
pd.read_excel(path, sheet_name=["Sheet1",1])尚、行や列の絞り込みなどはcsv同様なので試してみてください。
データ読み込み後のデータ抽出
csvファイルをjupyternotebookに読み込んだ後にデータの行や列を特定の条件で絞り込み加工したいケースをご紹介します。
列で絞り込む df.loc
データを絞り込む方法は「項目名」と「項目番号」があります。
事前準備として絞り込むためのsample_1.csvをPandasで読み込み変数df1に入れておきます。
df1=pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv")このdf1を利用して絞り込みたいデータの列名だけを表示するにはdf1.loc[:,[“列名1”,”列名2″]]のように項目名を指定します。
#絞りたい項目名指定
df1.loc[:,["商品ID","商品名"]]| 商品ID | 商品名 |
|---|---|
| 0 | たいやきみかん |
| 1 | たいやきおれんじ |
| 2 | やきいもたいやき |
| 3 | あんこたいやき |
| 4 | 栗たいやき |
項目名ではなく項目番号で指定したい場合はlocのまえにiを追加してdf1.iloc[:,[“列番号1”,”列番号2″]]とかきます。
※表示結果は同じなので省略しますが、ここでは6と7列のみを抽出しています。
df1.iloc[:,[6,7]]また、マイナス表記で項目指定することも可能で下記も結果が同じになる書き方です。
df1.iloc[:,[6,-1]]行で絞り込む
Pandasは条件によるデータ抽出方法がいくつもありますので私がよく利用するものを厳選して項目毎にわけて説明していきます。
レガシー手法とdf.quely手法
先程読み込んだdf1を利用して行の絞り込みを体験していきます。
中カテゴリが「たいやき」のものだけを絞り込むレガシー手法とquely手法の書き方は下記で表示結果は同じになります。
#レガシー手法
df1[df1["中カテゴリ"]=="たいやき"]
#quely手法
df1.query('中カテゴリ=="たいやき"')query手法ではシングルクォート「’」で囲んだ文字列内ではダブルクォート「”」を利用するか、反対のダブルクォート、シングルコートでも可能です。
| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-22 | おやつ | たいやき | 4000 | 1 | 4000 | 4 | 栗たいやき |
符号で行を絞り込む
符号を変えることで色々な条件の絞り込みが可能になりますので下記の符号の種類をご確認くださいませ。
- == 完全一致
- != 完全一致以外
- < しょうなり
- > だいなり
- <= しょうなりいこーる(以下)
- >= だいなりいこーる(以上)
df1のデータを元に体験できるコードをいくつか下記に記載致します。
##完全一致以外を抽出
#中カテゴリがたいやき以外を抽出する
#レガシー手法
df1[df1["中カテゴリ"]!="たいやき"]
#quely手法
df1.query('中カテゴリ!="たいやき"')
##売上金額が4000よりも少ないものを抽出する
#レガシー手法
df1[df1["売上金額"]<4000]
#quely手法
df1.query('売上金額<4000')見た目はqueryの方がすっきりしてわかりやすく思えます。
複数条件によるデータ抽出
今までは1つの項目に対して条件を指定してきましたが複数項目を利用して条件を絞る方法について説明していきます。
まずはand条件です。
#中カテゴリがたいやき、売上金額が3万円以上の条件で絞り込む
#レガシー手法
df1[(df1['中カテゴリ'] == "たいやき") & (df1['売上金額'] >= 30000)]
#quely手法
df1.query('中カテゴリ == "たいやき" and 売上金額 >= 30000')| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-09-30 | おやつ | たいやき | 4000 | 8 | 32000 | 11 | 定番たいやき |
| 2020-05-05 | おやつ | たいやき | 4000 | 10 | 40000 | 12 | さくらたいやき |
| 2020-10-29 | おやつ | たいやき | 4000 | 8 | 32000 | 13 | たいやきましまし |
| 2020-03-26 | おやつ | たいやき | 4000 | 8 | 32000 | 19 | たいやき一丁焼き |
| 2020-08-24 | おやつ | たいやき | 4000 | 8 | 32000 | 25 | たいやき御三家セット |
次にor条件です
#中カテゴリがたいやき、売上金額が3万円以上の条件で絞り込む
#レガシー手法
df1[(df1['中カテゴリ'] == "たいやき") | (df1['売上金額'] >= 30000)]
#quely手法
df1.query('中カテゴリ == "たいやき" | 売上金額 >= 30000')| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-08-04 | おやつ | たいやき | 4000 | 7 | 28000 | 3 | あんこたいやき |
| 2020-01-22 | おやつ | たいやき | 4000 | 1 | 4000 | 4 | 栗たいやき |
3つ以上の条件も指定可能ですが何を優先されるかで結果が変わってきますので優先したい条件を()で囲むことを意識します。
演算の優先順位はPython公式の説明をご覧ください。

#売上日が2020-12-22以降で売上金額が3万円以上か中カテゴリがたいやきのデータを抽出
#レガシー手法
df1[((df1['中カテゴリ'] == "たいやき") | (df1['売上金額'] >= 30000)) & (df1['売上日'] >= "2020-12-22")]
#quely手法
df1.query('(中カテゴリ == "たいやき" | 売上金額 >= 30000) & 売上日>= "2020-12-22"')| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき |
| 2020-12-25 | 果物 | みかん | 6000 | 8 | 48000 | 88 | ワイズマートのおすすめみかん |
| 2020-12-31 | 果物 | りんご | 7000 | 10 | 70000 | 116 | 新潟のりんご |
| 2020-12-26 | 麺類 | パスタ | 18000 | 4 | 72000 | 157 | コーンパスタ |
| 2020-12-28 | 麺類 | パスタ | 18000 | 3 | 54000 | 160 | 黄金パスタ |
正規表現によるデータ抽出
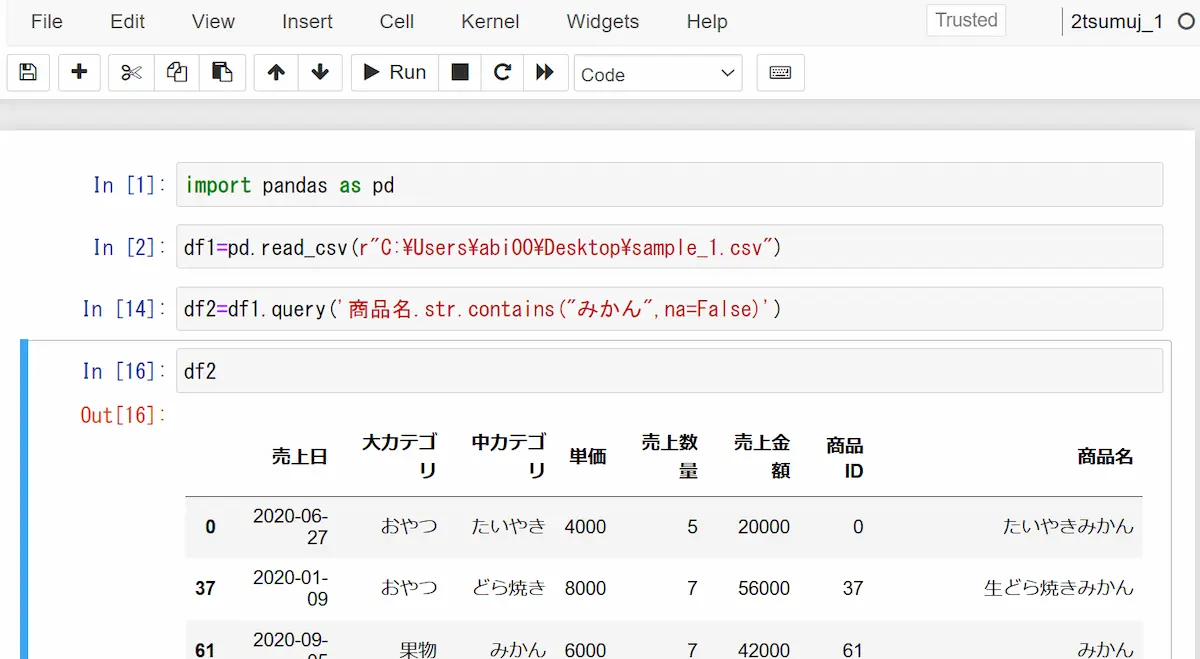
正規表現をこの記事で全て語ることは現実的ではないのでここでは正規表現での指定方法である「str.contains」の説明を致します。
下記例では曖昧検索で商品名にみかんが含まれるものを抽出するコードですが、もし値にnaやNAやNaNがあると下記エラーが出ます。
ValueError: Cannot mask with non-boolean array containing NA / NaN values
その場合はオプションのna=Falseを指定すればエラーを回避できます。
##Ageに2が含まれるものを抽出
#レガシー手法
df1[df1['商品名'].str.contains("みかん",na=False)]
#quely手法
df1.query('商品名.str.contains("みかん",na=False)')| 売上日 | 大カテゴリ | 中カテゴリ | 単価 | 売上数量 | 売上金額 | 商品ID | 商品名 |
|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん |
| 2020-01-09 | おやつ | どら焼き | 8000 | 7 | 56000 | 37 | 生どら焼きみかん |
| 2020-09-05 | 果物 | みかん | 6000 | 7 | 42000 | 61 | みかん |
| 2020-06-15 | 果物 | みかん | 6000 | 5 | 30000 | 62 | みかん愛媛 |
| 2020-09-01 | 果物 | みかん | 6000 | 6 | 36000 | 63 | みかん静岡 |
ランダムにデータ抽出 random_state
データの偏りを抑えて特定の件数を抽出したい場合はランダム(乱数)を使います。
ランダムサンプルを実施するにはdf1.sample(n=サンプル数)で抽出できます。
実行を繰り返すと毎回サンプル数の中で値が変わりますが、変えたくない場合はオプションのrandom_state=数字を利用します。
#タイタニックデータ891件からランダムに3件を抽出。 実行するたびに違うデータに入れ替わる。
df1.sample(n=3)
#ランダム3件は同じだが、何回実行しても結果は同じ。
df1.sample(n=3,random_state=1)
#上記とデータの中身は違うが機能は同じ
df1.sample(n=3,random_state=3)random_state=数値は好きな数値でよいですが大きすぎるとエラーになるので常識範囲内で設定してください。
ここのn=数字はデータの割合指定も可能であり、全体を100%として0~1の間で指定もできます。
#10%データ指定 全891件のうち89件がランダムに抽出されます。
df1.sample(frac=0.1)
#ランダム値の固定オプションも利用可能
df1.sample(frac=0.1,random_state=3)DataFrameの横結合と種類
ここからは私が作成した2つのサンプルデータを利用してデータを横結合する方法をご紹介していきます。
サンプルデータのありかがわからなくなった方はこちらに戻ってダウンロードしてください。
DataFrameを横に結合する方法はpd.merge(df1,df2,on=結合Key,結合方法)を使い結合方法とオプション指定は下記一覧になります。
| Keyの結合方法 | 指定コマンド |
|---|---|
| Keyが同じ項目の場合 | on |
| Keyが違う項目の場合 | left_on=”あああ”,right_on=”いいい” |
| 結合の優先指定 | 指定コマンド:how=”” |
|---|---|
| 内部結合(INNER JOIN) | inner |
| 左外部結合(LEFT OUTER JOIN) | left |
| 右外部結合(RIGHT OUTER JOIN) | right |
| 完全外部結合(FULL OUTER JOIN) | outer |
内部結合と外部結合の方法 pd.merge
2つのサンプルデータを用いて結合状況を目視でも確認する準備のためsample_1とsample_2を読み込みそれぞれ変数df1,df2にいれます。
df1=pd.read_csv(r"C:\Users\abi00\Desktop\sample_1.csv")
df2=pd.read_csv(r"C:\Users\abi00\Desktop\sample_2.csv")
print(len(df1),len(df2))最後にレコード数をprintしておりdf1が214件、df2が115件表示されます。
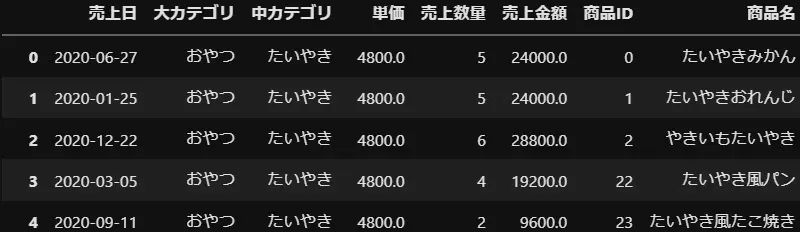
上記2つのデータを「商品ID」をKeyに内部結合(INNER JOIN)する方法と結果で112件が値として帰ります。
pd.merge(df1,df2,on="商品名")| 売上日_x | 大カテゴリ_x | 中カテゴリ_x | 単価_x | 売上数量_x | 売上金額_x | 商品ID | 商品名 | 売上日_y | 大カテゴリ_y | 中カテゴリ_y | 単価_y | 売上数量_y | 売上金額_y | 商品ID_2 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-06-27 | おやつ | たいやき | 4000 | 5 | 20000 | 0 | たいやきみかん | 2020-06-27 | おやつ | たいやき | 4800.0 | 5 | 24000.0 | 0 |
| 2020-01-25 | おやつ | たいやき | 4000 | 5 | 20000 | 1 | たいやきおれんじ | 2020-01-25 | おやつ | たいやき | 4800.0 | 5 | 24000.0 | 1 |
| 2020-12-22 | おやつ | たいやき | 4000 | 6 | 24000 | 2 | やきいもたいやき | 2020-12-22 | おやつ | たいやき | 4800.0 | 6 | 28800.0 | 2 |
| 2020-03-05 | おやつ | たいやき | 4000 | 4 | 16000 | 22 | たいやき風パン | 2020-03-05 | おやつ | たいやき | 4800.0 | 4 | 19200.0 | 22 |
| 2020-09-11 | おやつ | たいやき | 4000 | 2 | 8000 | 23 | たいやき風たこ焼き | 2020-09-11 | おやつ | たいやき | 4800.0 | 2 | 9600.0 | 23 |
上記をみると2つのことがわかります。
①レコード数が113件と減少した。
・内部結合は両DFにあるKey(ここでは商品名)が完全一致したものだけ抽出する。
②項目名の後ろに_x,_yがついた
・DataFrameを結合したさいに両項目名が同じだと区別する為に_x,_yが自動的に振られます。
sample_1(商品ID)とsample_2(商品ID_2)で項目名を微妙に変えている部分は一致していないので_x,_yは振られません。
今度は左外部結合(LEFT OUTER JOIN)で同じデータを結合したらどう変わるか結果をみるので,how=”left”を追加します。
pd.merge(df1,df2,on="商品名",how="left")結果は214件のレコードが表示され左側のdf1と同じ件数にるはずです。
左側に記載しているDF(ここではdf1)を全て表示したうえで右側のDF(ここではdf2)は商品IDが一致したものだけ表示しているからです。
右側を優先したい時は右外部結合(RIGHT OUTER JOIN)で,how=”right”を追加して実行すると115件が表示されます。
pd.merge(df1,df2,on="商品名",how="right")項目の並び順は最初に指定したDataFrameから表示されますので好みの方法を選択してください。
最後に完全外部結合(FULL OUTER JOIN)を実施するために,how=”outer”を指定します。
2つのDataFrameが1つにまとまりdf1とdf2のどちらのデータも全て表示され結果は216件になります。
#完全外部結合(FULL OUTER JOIN)
pd.merge(df1,df2,on="商品名",how="outer")df1が214件、df2が115件だがdf1とdf2の商品IDのユニークMAX値は217件ということになります。
結合Keyの複数指定
Keyを指定するポイントは大きく2つあります。
- 2つのDataFrameを結合する項目名称が違う場合はleft_on,right_onと書く
- 複数項目をKeyにするにはlist型で指定する
#keyが違う場合
pd.merge(df1,df2,left_on=["商品ID"],right_on=["商品ID_2"])
#複数keyで違う場合
pd.merge(df1,df2,left_on=["商品ID","商品名"],right_on=["商品ID_2","商品名"])
#keyが同じで複数の場合
pd.merge(df1,df2,on=["売上日","商品名"])
コメント